Linkup establishes SOTA performance on SimpleQA
Philippe Mizrahi
CEO & Co-founder
Linkup has achieved state-of-the-art (SOTA) performance on OpenAI's SimpleQA benchmark, scoring 90.10%. This performance surpasses both traditional AI models (e.g. Grok 3) and competing web-connected solutions (e.g. Perplexity)
03/12/2025 Update
Linkup launched a new version of its proprietary model, scoring a 91.0% F-Score on SimpleQA. This increases Linkup's lead against the competition (Perplexity, OpenAI, Exa, Tavily, etc…) and solidifies Linkup's position as the World's Best Search API for AIs.
Note: we have left the rest of the article as it was initially published on 02/21/2025.
TL:DR;
Linkup has achieved state-of-the-art (SOTA) performance on OpenAI's SimpleQA benchmark, scoring 90.10%. This performance surpasses both traditional AI models (e.g. Grok 3) and competing web-connected solutions (e.g. Perplexity). Our evaluations show that, when it comes to factuality, internet connectivity is more important than model size.
Note: this evaluation excludes research agents (e.g. OpenAI’s Deep Researcher, Perplexity’s Deep Research), which are designed to take much longer- seconds vs. minutes- to write research reports or long-form documents.
The Internet: An AI's Secret Weapon
A Large Language Model (LLM) is like a brilliant person who went into a cave a year ago - they don't know anything that happened since the end of their training. They can't tell you about yesterday's news or your company's latest products. By connecting your AI to the internet through an API like Linkup, we solve this problem - giving it access to the data it needs to generate high quality, grounded outputs.
This logic is quantitatively validated using OpenAI’s SimpleQA benchmark, which measures an AI’s factuality (more info in the appendix).
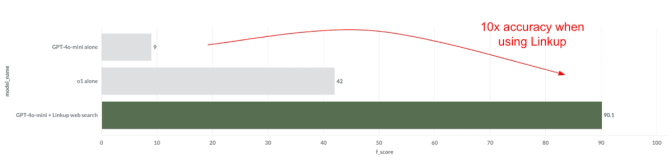
Our assessment demonstrates that integrating internet connectivity with GPT-4o-mini yields dramatic (x10!) performance improvements in terms of factuality. This makes GPT-4o-mini twice as accurate as o1, a model with much superior performance.
The architecture-agnostic nature of this integration enables consistent performance enhancement across multiple LLM frameworks, including Llama, Mistral, and Deepseek. These findings suggest that enhanced information access capabilities represent a fundamental shift in LLM performance optimization, potentially offering greater impact than traditional scaling approaches.
This quantitative evidence indicates that strategic integration of real-time information access may be a key driver of LLM performance enhancement, complementing existing model scaling approaches in the evolving AI landscape.
Linkup: The Best Way to Connect Your AI to the Internet
When it comes to web-connected AI, not all solutions are created equal. Here's how the numbers stack up:
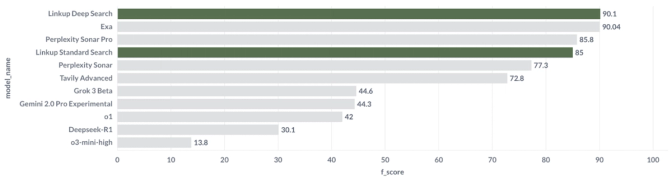
Linkup establishes a new State of the Art result on SimpleQA with 90.10% with Linkup Deep Search. Kudos to Exa for finishing close to Linkup at 90.04%. Linkup’s Deep Search beats the comparable Perplexity Sonar Pro (90% vs. 86%) and Linkup’s Standard Search beats the comparable Perplexity Sonar (85% vs. 77%).
How did we do it? We believe Linkup was able to achieve superior performance through:
- Advanced Search: Our proprietary algorithms ensure more relevant and accurate web results
- Data integrations: Linkup integrates natively with data sources to return high quality information
- Real-time Processing: The Linkup infrastructure is real-time by design and can surface information from published less than a minute ago
We’ll share a bit more in an upcoming technical blog post.
Interestingly, all the models with a web connection perform much better than the models without. Grok 3, which was just released, scores 45%, while Tavily scores 73%.
In our view, web retrievers like Linkup and LLMs should not be opposed. They should be used together to build AI applications, solving real world problems. Whenever accuracy is critical, using a web retriever can significantly improve performance. The internet is indeed AI’s secret weapon.
Our Methodology
To evaluate our performance, we used OpenAI’s SimpleQA benchmark and F-Score definition. Our script can be found here.
We ran this script for our Linkup API both in ‘standard’ - the fastest- and ‘deep’- the most comprehensive- modes, the ‘deep’ mode scoring the higher result.
For the other APIs (e.g. Perplexity Sonar Pro), we used the performances officially published by each of the companies (e.g. Perplexity) in blog posts or research papers. Sources can be found below.
The only exception to that is Tavily, which did not publish any results as far as we know. To measure their performance, we used the same script as we used to measure Linkup’s performance.
In this benchmark, we did not measure the performance of Deep Research Assistants like OpenAI’s Deep Researcher or Perplexity’s Deep Research, whose product behavior is less one of a web retriever and more of a report writing assistant, taking minutes to write long form reports.
For this benchmark, we selected the top industry players we identified. If you believe we missed anyone, please let us know at contact@linkup.so.
Looking Forward
Linkup’s focus is to build the best search for AIs, to power applications and the new generation of AI agents. And this is already happening. Linkup's search technology has started to quietly transform how people work with information.
The real story unfolds in offices and workspaces, where financial analysts uncover market trends in minutes rather than hours, and where customer service teams confidently answer complex questions on the fly. Teams using Linkup-powered apps are cutting their research time while actually improving their output - not because of flashy features, but because they're finding exactly what they need when they need it. There's something satisfying about seeing technology solve real problems, making Monday mornings a little smoother for people just trying to get their work done.
Get Started with Linkup
Ready to supercharge your AI with best-in-class web connectivity?
- Start building with Linkup for free!
- Join our community on Discord to connect with our team of engineers and AI researchers
- Follow us on X to stay up to date with our new releases
References and Sources
We used the AI-labs SimpleQA self-published performances, except for Tavily, for which we were not able to find one so we ran the evaluation ourselves: Exa, Perplexity, OpenAI, Google, Deepseek, Grok.
Appendix: About SimpleQA
SimpleQA is OpenAI's new benchmark for measuring AI factuality, featuring 4,326 questions across diverse topics including science, politics, arts, and technology. For complete details about SimpleQA methodology and implementation, visit OpenAI's documentation.