
Your AI searched the web. It just didn't read it.
The Linkup Team
Your AI searched the web. It just didn't read it. A native web search answer can cite sources, link URLs, and still contain facts that appear nowhere in those sources. The answer looks grounded - there's no way to tell from the output that it isn't. That's the failure mode this post documents: not a worse answer, an unverifiable one. This is a writeup of a live demo comparison between Claude's native web search and Linkup's retrieval API - what we tested, what we found, and why it matters for anyone building production AI systems on top of web search.
The setup
Six research questions, run sequentially with identical prompts on both tools:
1. AI-related layoffs in the US over the past 6 months - numbers and sentiment
2. New energy storage projects for AI data centers
3. Security certifications for enterprise and financial services
4. eReg - 21 CFR Part 11 compliance status of various companies
5. European automotive news, last week, summarized by brand
6. SOFC technology landscape, history, and competitive dynamics
For each question: run native WebSearch first, save the raw output, then run Linkup, save that output, then compare both against the same standard. No post-processing on either side.
The comparison led with a TL;DR and a winner. Linkup won 5 out of 6. The one tie was on certifications - a static, well-indexed compliance page that both tools hit directly.
What the two tools actually return
This is the part most people haven't looked at closely.
When Claude uses its native web search tool, what lands in the context window looks like this:
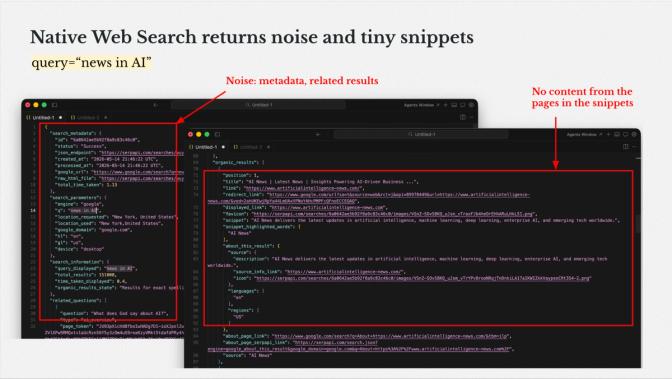
Each result is a title and a URL. No content snippets. The tool then generates a synthesized answer - invisibly, before Claude reasons over it. By the time Claude produces a response, the synthesis has already happened. There is no visibility into which facts came from which URLs, whether the underlying pages were actually fetched, or whether the content was current. The output is a finished answer that looks sourced.
Linkup returns this instead:
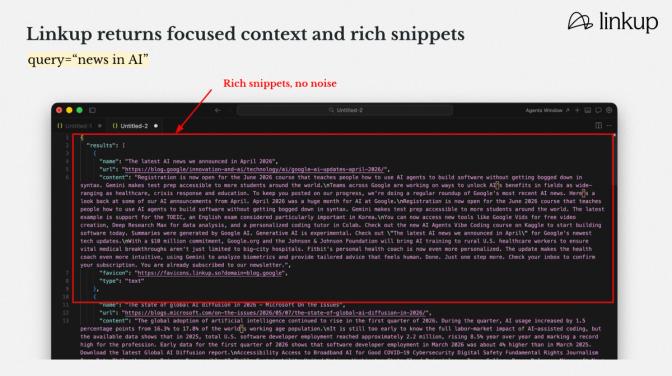
Every result has a `content` field - 100 to 400 words of extracted page text, pulled directly from the article. Claude receives the raw material and reasons over it. The synthesis is visible, traceable, and interruptible.
This is the structural difference everything else flows from. It's not about which tool finds more results. It's about what the model has to work with when it produces an answer.
The automotive news query- where it broke
The most revealing test was the auto news query: "Summarize last week's news for BMW, Mercedes, Porsche, VW, Renault, Ferrari, Stellantis - date, headline, implications, details, source."
Native search returned 8 story lines across 5 brands. Linkup returned 15 across 7. That coverage gap alone is significant for anyone running competitive monitoring or market intelligence workflows. But the more interesting problem wasn't coverage - it was what happened inside the 8 stories native did return.
After the initial run, a second pass was done: every URL from native's link list was fetched through Linkup to check whether the underlying content matched what the synthesized answer claimed. Five issues came up:
1. Wrong product name.
Native's answer referred to Ferrari's new EV as "Elettrica." The actual car is called Luce. It launched in May 2026. The source native pulled was a January 2026 prediction article - published before the reveal - that speculated on a name that turned out to be wrong. Because native search never exposed the publication date or article content, Claude had no signal that it was reading a five-month-old forward-looking piece instead of a product announcement.
2. Forward-looking article presented as current news.
The Porsche GT2 RS story came from an article dated January 2026 describing a car that was "years in the making" with prototypes being spotted. By the time of the query, this was not news. But native's synthesized answer presented it alongside June 2026 stories without any date differentiation.
3. Paywalled source, no content confirmed.
The BMW/Mistral AI crash simulation headline came from MarkLines a subscription automotive data portal. When that URL was fetched through Linkup, it returned a navigation page and a locked content wall. No article body was ever accessible. The headline made it into the answer anyway, sourced to a page that contained no readable content.
4. Currency conversion inherited silently.
Native's answer cited a $69B figure for Stellantis's FaSTLAne 2030 strategic plan. The actual figure in Stellantis's press release is €60B. An intermediary source - AutoGuide - had converted it to dollars. Native picked up that conversion without flagging it. The primary source says euros. The answer says dollars. If you're building a financial monitoring tool on top of this, that's not a rounding error.
5. URL in the link list, content never used.
One article - the CEO churn piece from Automotive News - appeared in native's link list but none of its content surfaced in the synthesized answer. The model cited the page implicitly by including it as a source, but nothing from that article is traceable in the output.
None of these are model failures in the traditional sense. The model synthesized correctly from the inputs it received. The inputs were the problem.
Where the gap is smallest - and why that matters
The one question where both tools performed identically was security certifications. Both returned the same nine certifications, the same dates, the same source pages.
That's expected and worth understanding. The company we looked for publishes a well-structured security page that's heavily indexed. The information is static, authoritative, and lives on a single domain. Any competent search tool will find it.
The gap opens on anything time-sensitive, multi-source, or buried in less-indexed corners of the web: earnings calls, regulatory filings, vendor product specs, regional news, niche analyst reports. That's exactly the category of query that matters most for financial workflows and AI product teams doing competitive or compliance research.
What this means if you're building on web search
The core problem is that native synthesis is unauditable by design. A fact can't be traced back to a source sentence. There's no way to check whether a page was actually fetched, whether a result was behind a paywall, or whether the content was five months out of date. The answer looks the same either way.
For internal tools or consumer products where approximate answers are acceptable, that may not matter. For anything where a decision gets made based on the output, a trade, a compliance check, a due diligence memo, a different architecture is needed.
Specifically:
- Per-result content extraction, not titles. The model needs the actual text to reason over, not a signal to infer from.
- Crawl timestamps per result, not just publication dates. A page can be published in 2026 and cached in 2024.
- Source-level control. For regulated workflows, the ability to whitelist primary sources - official press offices, regulatory databases, verified newswires - and exclude SEO aggregators is not optional.
- A traceable output format. Every claim in the final answer should map to a specific sentence in a specific fetched document. If it doesn't, the system is doing inference, not retrieval.
The test to apply is simple: if someone challenges a fact the AI produced, can you show them the source sentence? Not the URL, the sentence. If the answer is no, the retrieval layer is doing inference disguised as search.
That's what the test showed. The queries are listed above and both tools are straightforward to call. The results will look similar - the structural difference doesn't change between runs.


